beijingwalker
ELITE MEMBER

- Joined
- Nov 4, 2011
- Messages
- 65,191
- Reaction score
- -55
- Country

- Location
A New AI Research from China Introduces a Multimodal LLM called Shikra that can Handle Inputs and Outputs of Spatial Coordinates in Natural Language
By Aneesh TickooJuly 8, 2023
Multimodal Large Language Models (MLLMs) have significantly developed in recent months. They direct people’s attention to Large Language Models (LLMs), where people may discuss the input image. Although these models can understand visual content, they cannot communicate with users about the exact locations of the material. Both users and the models cannot provide specific positions for the stated material in a picture. In contrast, as illustrated in Figure 1, distinct areas or items in the scene are often addressed in daily human conversation, and individuals can talk and point to specific regions for effective information sharing.
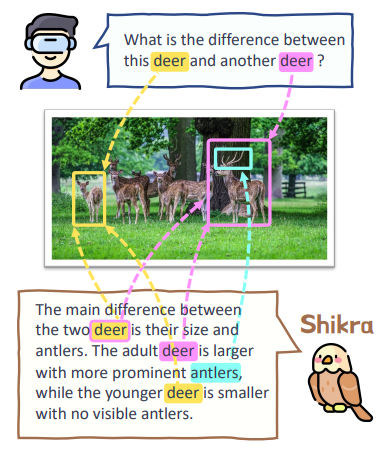
Figure 1: Referential Dialogue (RD) demonstration. Users can ask inquiries and point to certain regions. Shikra will then, if necessary, specify the regions while responding.
They call this kind of communication referential dialogue (RD). Many fascinating applications will result if an MLLM performs in this area. Users may indicate anything to communicate with the AI assistant, for example, while using Mixed Reality (XR) headsets like the Apple Vision Pro. When necessary, the AI assistant can show the immediate area in the field of vision. It also helps visual robots interact with people by understanding their unique reference points. Assisting consumers to learn more about objects of interest in a picture helps online buying. They develop MLLM in this study to lift the curtain on a referential conversation.
Researchers from SenseTime Research, SKLSDE, Beihang University, and Shanghai Jiao Tong University developed Shikra, a unified model that can handle inputs and outputs of spatial coordinates, which is what they created. Without using additional vocabularies or position encoders, all coordinates, both input, and output, are provided in natural language numerical form. An alignment layer, an LLM, and a vision encoder are all parts of the Shikra architecture. They make Shikra uniform and straightforward by not introducing pre-/post-detection modules or other plug-in models. They offer numerous user interactions that users may use to compare the variations between various areas, enquire about the meaning of the thumbnail, talk about certain items, etc on their website. Shikra can answer every question with justifications, both vocally and geographically.
The vision-language (VL) job of referential discourse supersets several others. Shikra, proficient in RD, can naturally do tasks like Visual Question Answering (VQA), picture captioning, and location-related tasks, like Referring Expression Comprehension (REC) and pointing, with promising results. Additionally, this essay discusses interesting issues like how to depict location in a picture. Are MLLMs from the past able to understand absolute positions? Can using geographical information in reasoning lead to more precise responses to questions? They hope these analytical experiments will stimulate more MLLMs research in the future.
The key contributions of this essay are as follows:
• This essay presents the activity of Referential Dialogue (RD), which is a crucial part of regular human communication and has many practical applications.
• Shikra, a generalist MLLM, is offered as the RD. Shikra is straightforward and unified without adding new vocabularies, pre-/post detection modules, or other plug-in models.
• Shikra easily manages hidden settings, resulting in various application situations. Without any fine-tuning, it also shows good results on common visual language tasks, including REC, PointQA, VQA, and image captioning. The code is available on GitHub.
A New AI Research from China Introduces a Multimodal LLM called Shikra that can Handle Inputs and Outputs of Spatial Coordinates in Natural Language
Multimodal Large Language Models (MLLMs) have significantly developed in recent months. They direct people's attention to Large Language Models (LLMs), where people may discuss the input image. Although these models can understand visual content, they cannot communicate with users about the...
 www.marktechpost.com
www.marktechpost.com